
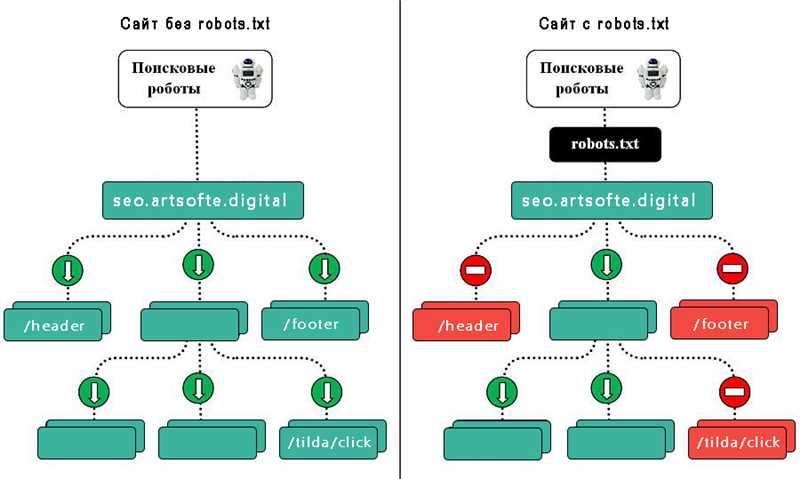
Robots.txt – это текстовый файл, который размещается на сервере и предназначен для управления поведением поисковых роботов на сайте. Он сообщает роботам, какие страницы сайта им можно индексировать, а какие – нет. Для того чтобы поисковая система смогла найти и проиндексировать ваш сайт, robots.txt выполняет важную роль.
Индексный файл robots.txt позволяет веб-мастерам контролировать доступ к различным разделам и файлам на сайте. С его помощью можно запретить индексацию некоторых страниц, таких как административные панели или разделы с конфиденциальной информацией. Также с помощью robots.txt можно запретить индексацию и краулинг файлов определенного формата, таких как изображения или видео.
Основной принцип работы файла robots.txt основан на протоколе «robots exclusion protocol». Этот протокол устанавливает правила доступа для поисковых роботов и определяет, какие страницы им можно индексировать, а какие нет. Если веб-мастер желает запретить доступ к определенным разделам сайта или файлам, он просто добавляют соответствующие команды в файл robots.txt.
Определение файла robots.txt
Основная цель файла robots.txt — это предоставить инструкции роботам поисковым системам относительно доступа к различным страницам и файлам на сайте. С помощью этого файла владельцы сайтов могут контролировать процесс индексации и оптимизировать поисковую видимость своего сайта. Однако, файл robots.txt не является абсолютной гарантией защиты от индексации и поиска.
Структура файла robots.txt
Файл robots.txt состоит из одного или нескольких «User-agent» и «Disallow» директив. «User-agent» указывает на имя робота поисковой системы, к которому применяются следующие «Disallow» директивы. «Disallow» указывает на страницы или каталоги, которые не должны индексироваться и обрабатываться данным роботом. «Disallow» директивы указываются относительно корневого каталога сайта и могут содержать символы подстановки.
Например:
| User-agent: | Disallow: |
|---|---|
| * | /private/ |
| Googlebot | /images/ |
| Bingbot | /admin/ |
В данном примере «*», «Googlebot» и «Bingbot» являются именами роботов, которым применяются следующие «Disallow» директивы. Таким образом, страницы и каталоги, начинающиеся с «/private/», «/images/» и «/admin/», не будут индексироваться роботом «*» (что можно интерпретировать как «все роботы»), роботом «Googlebot» и роботом «Bingbot» соответственно.
Функции и возможности robots.txt
Основная функция robots.txt – это ограничение доступа для поисковых роботов к определенным разделам сайта или к конкретным файлам и папкам. Это полезно в случае, когда на сайте есть разделы, содержимое которых не должно быть индексировано поисковыми системами или доступно для общего использования. Например, административные панели или файлы с конфиденциальной информацией.
Однако robots.txt позволяет не только ограничивать доступ к отдельным разделам или файлам, но и указывать способ индексации страниц. Например, можно указать, что роботы должны индексировать только основное содержимое страницы, игнорируя боковые панели или блоки с рекламой. Это помогает оптимизировать работу поисковых роботов и повышает качество индексации сайта.
Кроме того, robots.txt может использоваться для управления скоростью сканирования сайта поисковыми роботами. Это полезно для сайтов с большим количеством страниц или для сайтов с ограниченной пропускной способностью. В файле robots.txt можно указать максимальное количество запросов в единицу времени, которые разрешено выполнять поисковым роботам, чтобы не перегружать сервер и не нарушать работу сайта для других пользователей.
В целом, для большинства владельцев сайтов использование robots.txt не является обязательным, но имеет ряд преимуществ. Правильная настройка robots.txt помогает оптимизировать работу поисковых роботов, защитить конфиденциальную информацию и повысить качество индексации сайта в поисковых системах.
Зачем нужен индексный файл robots.txt
Основная задача robots.txt — обеспечить контроль доступа к различным разделам сайта для поисковых систем. С его помощью можно указать, какие страницы сайта следует индексировать, а какие наоборот, исключить из индекса. Это особенно полезно в случаях, когда веб-мастерам необходимо скрыть конфиденциальную информацию или предотвратить индексацию дубликатов страниц.
Индексный файл robots.txt позволяет также указать пути карта сайта (sitemap.xml) для упрощения процесса индексации. Благодаря этому, поисковые системы могут быстрее и более эффективно просканировать сайт, что способствует повышению его видимости в выдаче результатов.
Однако, не стоит полагаться исключительно на индексный файл robots.txt для защиты конфиденциальных данных на сайте. Хотя он помогает предотвратить индексацию некоторых страниц, он не является надежным средством безопасности. Более эффективными методами защиты могут быть использование аутентификации, правильная настройка прав доступа и шифрование данных.
Итог:
- Индексный файл robots.txt позволяет веб-мастерам контролировать процессы индексации и сканирования сайта поисковыми системами;
- Он позволяет указать, какие страницы следует индексировать, а какие исключить из индекса;
- Индексный файл robots.txt также упрощает процесс индексации путем указания пути к карта сайта;
- Однако, индексный файл robots.txt не является надежным средством безопасности и не должен использоваться как единственное средство защиты конфиденциальной информации на сайте.
Наши партнеры: